2022/08/10,许晟
加了三个月的班,我们的Trainium芯片和AWS上的trn1 instance终于要面世啦!毕业后加入AWS Annapurna labs的这一年半,我学到了很多,也越来越喜欢这份工作。最近经常和朋友们聊起AI芯片和编译器这个飞速发展、激动人心的领域。在这里总结记录一下这一年的收获和感想。
1/ 我们实验室是做什么的
我们是帮AWS(Amazon Web Services)搞芯片的,又快又省钱的芯片。
Annapurna labs在2011年由几个以色列工程师创立,一开始以做CPU芯片为主。2016年被Amazon收购以后,就一直是AWS的”急先锋”。先是和EC2的团队合作,推出了AWS Nitro这个虚拟化系统,把EC2上所有实例都大大的加速。然后又推出了Graviton系列芯片,目前仍然是AWS上price performance最好的CPU芯片。Price performance就是用价格除以性能,在单位性能下,价格越低越好。对于那些每天都得跑成千上万次计算的大公司,用我们的芯片能让他们每年省下几百万甚至几千万美金。
最近十年AI崛起,掀起了一波机器学习的潮流。尤其是深度学习这个分支,应用到了我们生活的方方面面,比如各种app和网站的推荐算法,语音识别,视觉识别等等。深度学习模型的大小也在爆炸性增长,从几年前的几百万参数,到最近新出模型的几百亿参数。这些都对底层的计算平台提出了很高的要求。所以这些年,许多科技大厂都开始搞自己的AI芯片,各种芯片startup更是如雨后春笋。
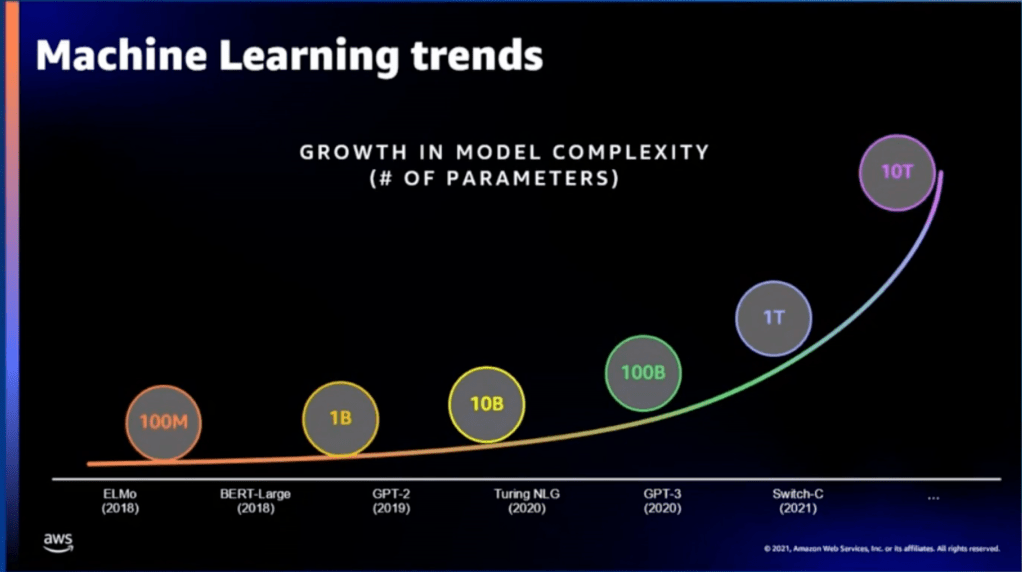
AWS坐拥世界上最大的云计算平台,有极好的用户基础,当然也不甘落后。2018年,在AWS的AI战略布局下,Annapurna labs开始转型做机器学习芯片。从2019初的AWS re:Invent宣布,到2020年正式推出Inferentia芯片和AWS inf1 instance,是当时云端上深度学习inference price performance最好的instance。Inferentia是专门为深度学习设计的芯片。这种专门为一个领域设计的芯片叫ASIC。ASIC牺牲了普适性,但是收获了高性能。
这里提一句,深度学习分为training和inference两步。深度学习模型先经过training把所有误差降到最低,然后就可以开始投入使用,也就是开始inference。training的过程是很难很慢的,大的模型需要训练几天甚至几周。好在过程是一次性的,一个train好的模型可以被不断的被使用。与此相比,大的商用模型每天要跑上万次inference。所以一般来说,inference才是公司支出的大头。Inferentia芯片就是专攻inference。
Inferentia面世不久就收获了许多大大小小的客户。在Amazon内部,我们最大的客户是Alexa,用我们的芯片把Alexa加速了25%,成本降低了30%。在Amazon外部,我们最开始的客户包括Airbnb, Snapchat, Pinterest等,后来又逐渐吸纳了Bytedance, Facebook, Apple等大公司。

Inferentia获得成功之后,团队又开始马不停蹄的开始下一代芯片Trainium的开发。Trainium不仅在inference上面比Inferentia强了许多,而且支持training。经过了两年的努力,Trainium芯片和相应的trn1 instance终于要正式上线了!
这里必须提一下业界老大哥Nvidia英伟达。Nvidia从几十年前就开始造GPU,经验丰富。这些年他们接连推出T4, A10G, A100等针对机器学习的GPU。根据2020年的市场调查,Nvidia在AI芯片的市场占比在80%以上。有趣的是,Nvidia和AWS其实是紧密的合作伙伴,T4/A10G在AWS上叫G4dn/G5 instance, A100在AWS上叫P4d/P4de instance。
我们芯片的原理和GPU完全不同,不过我们必须得比GPU的性能更好才能吸引到顾客。我们的Inferentia在最常用的那些模型上比G5平均快了30%,便宜了50%。

而新推出的Trainium,跟A100在GPT模型上一样快,便宜了50%。比A100在BERT模型上快了50%,便宜了2.5倍(BERT和GPT分别是目前最常用和最火爆的深度学习模型)。鉴于A100是目前市面上最快最强的AI GPU,所以Trainium也算是跟上时代了!
另外,光有好性能还远远不够,顾客的体验和易用性同样的重要。对此,我们有一整套软件的服务。顾客从GPU instance迁移到inf1/trn1上,只需要在tensorflow/pytorch里面加不到五行代码。

当然,比起Nvidia的GPU、Google的TPU,我们在普适性以及软件工具链的成熟度上都还有很长的路要走。可是考虑到Nvidia和Google起步比我们早了几年,而且在这个领域都有上千人的团队;相比来说,Annapurna labs上下不足200个工程师,我所在的编译器团队更是缺人手,只有不到20人。只用了4年的时间走到这一步,我觉得我们很棒了!
可以说,比起不少芯片的初创公司,Annapurna labs目前发展的算是非常顺利了。除了团队的不懈努力外,必须得感谢AWS这个独一无二,全球第一的云计算平台,为我们提供了源源不断的客源。后续我们的目标是继续以2年一次的频率推出更强的芯片。
2/ 我的团队 – 深度学习编译器
什么是compiler(编译器)呢?简单来说,编译器就像是一个翻译机,把程序员写的代码翻译成底层芯片能懂的语言(也叫ISA)。有趣的地方在于,一份代码有多种翻译的方式,不同的方式生成的结果在性能上天差地别。
所以编译器有两大功能:
- 翻译。这里得考虑到芯片的各种限制,生成的ISA必须是可运行的
- 优化。优化做得好,能让性能有几十倍乃至百倍的提升
在传统的编译器领域,最著名的编译器就是LLVM。LLVM往上能接收几乎所有计算机语言,把它们翻译成LLVM自己的语言(也叫IR),往下能接通绝大部分底层的ISA。LLVM提供的核心价值是基于IR的一整套复杂优化。
不过LLVM的优化主要针对CPU的(普通电脑里面装的芯片),对AI芯片不适用。我们所做的深度学习编译器和传统编译器主要有两大不同:
- 传统编译器做的优化大部分是对任何硬件都适用的。而我们的编译器专门针对我们的芯片,所以我们有更多的信息,也能做传统编译器做不了的优化。
- 我们的编译器只需要能处理深度学习的模型,而传统编译器需要能处理一切可能出现的代码。深度学习的模型往往有比较整齐的结构,由一些常见的operator,比如matmult/batchnorm等组成。我们的编译器可以利用这些结构来简化优化的算法。
听上去深度学习编译器好像比传统编译器简单?其实并不。这个新的领域带来了一系列前所未有的难题。我们团队的好些老家伙就是从传统编译器跳槽过来,希望做一个先行者去挑战这些崭新的问题。具体有哪些难题呢,且听我后面娓娓道来。
这几年,和AI芯片一样流行的还有一个词,就是hardware-software codesign(软硬件协同设计)。硬件就是芯片。而在我们这,软件分为三个团队:framework团队负责和客户接轨,并做一些横跨多个芯片的功能,比如distributed training;runtime团队负责芯片的运行环境;而我所在的编译器团队负责优化性能。
用一个简单的比喻,我们的芯片就像是一辆F1赛车,有各种酷炫的功能和黑科技,而编译器就像是赛车手。赛车和车手是相辅相成的。赛车的各种参数决定了速度的上限,但只有顶尖的车手才能发挥出赛车全部的性能。
一方面来说,硬件指导软件,因为编译器需要针对芯片的特性和限制来做优化。另一方面来说,软件也指导硬件,因为我们在编译器优化过程中会发现芯片的许多不足,然后针对这些不足和硬件工程师们共同设计下一代的芯片,弥补这些不足。总之,软硬件缺一不可。
3/ 我的旅程
自从研一上了CMU的编译器课,我就爱上了这个领域。CMU有一个自己的C0语言,是C的语言的精炼版,用来训练大一的新生。那节课就是要学生们两两组队,从零开始给C0语言写一个编译器,是CMU计算机著名的两大难课之一(另一个是操作系统)。当时课上有个scoreboard,给所有团队的优化排名,优化的越好排名越高。我和队友为了冲scoreboard,每天寻找性能瓶颈,然后读论文,自己设计算法并实现,最后能看到性能肉眼可见的加强。我对于这个流程深深着迷,甚至超过了打游戏带给我的乐趣。后来,我又回来当了这节课的助教,设计了几个新的优化project。值得小小吹一下的是,我在助教期间继续优化自己的编译器,最后比CMU官方的C0编译器平均快了2.5倍,我的编译器也成为了这节课用来做性能比较的官方选择。
2020年底,到了找工作的季节。本来我已经情定苹果的操作系统团队了,我投的那些为数不多的编译器团队也都如石沉大海,没有回音。在一个周五晚上的11点(这很Amazon),我冷不丁收到了一封招聘邮件,说是AWS做AI编译器的Neuron团队。当时的感觉,就跟在茫茫人海中,突然来自心动女孩的惊鸿一瞥。我立刻回了邮件,10分钟后,我们就约好了第一轮面试的时间,10天后就收到了offer。后来,我也深深的体会到我们团队这种move fast,一切效率为先的风格。
进入团队后,我是忐忑不安的。同事们都是清一色编译器博士毕业,许多在业界浸淫几十年,还有几个教授。而我只是一个接触这个领域一年不到的小白。还好团队里的大家都很友好,我也遇到了一个好大哥HB。HB是我短短的25年人生里见过最牛逼的程序员了,如果放在古代三国,那绝对是以一当百的猛将。他不仅写代码像个机器一样快,而且在系统设计和优化思路上有一针见血的见解,数学功力也是深不见底。很多我百思不得其解的难题,他拍脑袋想出来的思路总让我拍案叫绝。每天跟着同事们,学习他们解决一个个难题的思路,让我得到了很大的成长。
(下面这几段太多专业术语,不感兴趣的话可以直接跳到后面哈哈)
都有哪些难题呢,举一些简单的例子吧。比如我们芯片用的是一个software managed cache,每个tensor啥时候进cache,啥时候出cache,都得由编译器决定。我们的cache还是一个2D的cache,分成了许多能并行读写的partition,所以每个tensor用什么2D的形状,放在cache里的哪一个地方,也由编译器决定。每个instruction的顺序需要编译器schedule。不同的instruction在不同的engine上运行然后需要synchronize。每个instruction读每个tensor的memory access pattern需要决定。每个instruction读的tensor大小也由编译器决定。等等等等。这里面的大部分决定都包含取舍,比如把instruction读的tensor变大的话,单个instruction的性能会提升,但是pipelining会不好,而且会让cache memory容易溢出导致spilling和reload。
用计算机的术语来说,我们的编译器需要解决一系列的NP-hard问题。NP-hard就是目前无法在多项式时间内找到最优解的问题。好在我们能利用深度学习的模型的一些规律,找到heuristics来近似求解这些难题。
我的第一个project是做batch loop的scheduling和distribution。目标是在不超出cache memory的前提下,尽量减少weight reload,并且做好instruction的vectorization。可惜我只来得及做出来一个原型,就被叫去做下一个project了。今年暑假来了一个实习生小哥哥,和我合作继续做这个project。
我的第二个project是做tensor layout optimization and tiling。这里提一句,深度学习里面矩阵乘法是大头,所以我们的芯片中最核心的部分叫systolic array(是CMU的一个老教授发明的),是一种能超速并行做矩阵乘法的元件。而systolic array对输入和输出的tensor的2D形状有硬性的要求:比如哪一些dimension在单个partition里,哪一些dimension横跨多个partition,哪一些dimension会被unroll成多个instruction。这就叫tensor的layout。当然除了矩阵乘法,一个模型中还有许多别的operator需要被决定layout。有时候,一个tensor被多个operator用,而它们的layout不同,就必须生成合适的tensor transpose。
简单的来说,layout optimization就是给整个模型在我们硬件上确定一个骨架,既要决定每个tensor的layout,也要决定中间如何做transpose。然后tiling会进一步确定每个tensor和operator的2D形状,以及memory access pattern。这是一个NP-hard的问题。
layout做得好,那最后生成的instruction数量和transpose数量就少,既提升性能又提升编译速度。另外,好的layout和tiling还能让后面的fusion更容易,也会让memory access更有效率,并减少需要读写DRAM的次数。骨架生成的好,后面的整个编译流程都会受益。
经过了几个月的冥思苦想,我总结了之前搜索算法的不足,从头设计了一个新的layout算法,比之前的算法在复杂的training模型上平均少了接近10倍的instruction,大大提升了性能和编译速度。这是我人生中设计的最复杂的算法了,到现在我也有点侥幸一开始设计时候的假设和推论最后真的证明是正确的。这个project的成功也大大增强了我的信心,团队中的人也开始把我当成这一小块的专家,有相关问题就来找我解决。
中间我除了日常维护这个复杂的layout和tiling系统,又做了若干个project,比如去找编译器各个环节的算法瓶颈,把编译速度提升了2倍。
而我最近的一个project是今年5月开始的。在组内大佬Ron的带领下,我们一个10人的小团队开始优化GPT和BERT training在Trainium上的性能,目标是超过GPU。5月的时候我们还比GPU差3倍的性能,简直像不可能完成的任务。而到了8月,编译器的优化让我们抹平了和GPU的差距。
在这个过程中,我发现了不少性能的瓶颈,和硬件工程师们讨论后共同设计出了几个新的硬件instruction,应用于编译器的优化中。另外,我在优化编译器另外几大难点,比如loopfusion和vectorization的过程中,对整个编译器有了更深刻的了解。
我也意识到了未来的努力方向。虽然在这个过程中,我的各种优化提升了不少性能,但往往都是Ron或者HB发现问题,而我去解决问题。我没有他们那种对芯片,对编译器,对深度学习那种总揽全局,高屋建瓴的视野。希望未来我也能学到他们的这种能力。
最后我想谈谈对这个领域未来的展望。一开始,我担心自己做的东西太底层,会越做视野越窄。现在我越来越感觉,AI芯片或许只是目前流行一时,但未来对高速计算平台的需求只会越来越大。无论是智能汽车,强AI,VR/AR,区块链等等,他们的共同点都是对算力有极高的要求。所以我们在做AI芯片所学到的加速原理,软硬件协同设计的经验,未来都能派上用场。我认为这是一个很有前景的领域,无论在美国还是国内!
4/ 一些七七八八的感受和吐槽
我非常喜欢我们团队,因为工作很有意思,有初创公司的活力,而且团队的氛围特别好。去年我还把我的好朋友,大神SX也骗来了我们的framework团队搞机器学习。
但值得吐槽之处也是不少的。比如说,我们湾区的办公室没有食堂!每天中午得和同事下楼去找吃的,基本上还得自己付钱。和湾区别的公司真是没法比。另外,我们的大老板对入职级别卡的极严,我们组有一个和我同一天入职的小姐姐,对口专业博士毕业,能力超强,连她都只给了初级工程师。
有朋友问我推不推荐来Amazon呢?我觉得挺看团队的。我们团队虽然偶尔加班,但是总的来说工作时间和放假都很灵活,oncall不辛苦也不会被半夜吵醒,历史上也从来没有被pip(末位淘汰)过人,还是很推荐的。
最后,我们团队(AWS Neuron team)还在努力招人,尤其是毕业生或者刚工作几年的!组内现在是大佬多,新人少,编译器领域又特别难招人。不需要对芯片、编译器有多深的了解(有的话加分!),最重要的是喜欢算法,喜欢优化,执行力和学习能力强。可以找我或者直接联系我们的组长Don。对research更感兴趣的话也可以考虑我们的兄弟团队,李沐大神带领的science team,他们和我们有深度的合作。快来加入我们吧!

3 responses to “Trainium芯片要上线了!我的工作一年感悟”
想要挑战老大哥NV的地位是很不容易的,加油!
LikeLike
现在回头看,才知道当年方向都是错的。
LikeLike
确实踩了不少坑,这几年团队成长了非常多
LikeLike