最近,我陷入了认知危机。表面上蓬勃发展日新月异的AI领域,却让人感到深深的焦虑。咱们人类的未来真的还掌握在自己手中吗?AI会不会失控?我们的子子孙孙还能快乐的生活吗?
以前,每天干着活,还能说服自己是在为社会做一点微薄贡献。最近呢,总害怕是在助纣为虐。
今天偶然想到一个不成熟的管控AI的思路,让我重燃了对未来的希望,在此记录下来。
什么是AI Safety?
这一年来,AI的发展速度可谓疯狂。领域内绝大部分的顶级研究者都认为,通用人工智能(AGI)的到来只是时间问题了。5年,10年,20年?无论如何,我们的社会体系,法律体系,经济体系和外交体系,都还远远没有准备好。
简单来说,我们可以把智能(intelligence)理解成一个 information processing system。接受信息,处理信息,然后输出信息。我们的脑子,也就是人类的智能,只是无数可能的智能的其中一种而已。而现在即将降临的AGI,会是我们从未见过的另外一种智能,会是一个全新的物种。这个智能将会在各方面碾压人类,极可能是人类无法理解的。一旦AGI脱离管控,人类的未来将岌岌可危。
有人说,那我们能暂停AI的研究吗?上个月,有洞见的科学家提出了暂停6个月AI研究的提案,但很快就石沉大海。马一龙大哥,前脚在提案上签了名,后脚就给推特加订了一万个AI芯片。说到底,现在AI的经济价值太大了,这块大饼你不抢别人也会去抢。所以大家虽然都知道前途凶险,但还是各自卯足了劲儿往前冲。
“We’re rushing towards a cliff, but the closer we get, the more scenic the views are.”
AI Safety & Alignment,研究的就是怎么才能让未来的AGI安全可控,只为人类的利益找想。
关于这个课题,强烈推荐Lex fridman的podcast,尤其是Max Tegmark的这一期。我的同事Daniel做的”The Gradient Podcast”也有许多相关的采访。走向AI Safety的第一步,就是唤醒大家的认知,让所有人都意识到这是一个多么紧迫和重要的问题。
我的想法
今天偶然有个不成熟的想法,希望能抛砖引玉。
我们知道,人无完人。我们每个人都会有善念和恶念,不可避免的日常会有一些离经叛道的想法。但是君子论迹不论心。换句话说,看一个男人,不要只听他说了什么,要看他做了什么哈哈哈。
作为一个对神经科学一窍不通的人,我粗浅的理解人脑可以分为一个“提供建议”的模块 (thought generation module – TLM),和一个“做决定”的模块 (decision making module – DMM)。就像当我遇到很不爽的人,TLM会建议我和他干一架,但是有理智和道德的DMM会控制住我,让我乖乖回家。
AI系统也是一样的。现在的大模型和未来的AGI,不可避免的会产生一些对人类不利的想法。最麻烦的是,大模型和AGI如此庞大,按照现有的技术水平,是没法完全理解(interpret)和验证(verify)的。
我的想法就是,能不能把AI系统也分成两块。一块呢,是TLM,极度聪明极度复杂,可是毫无实权,只能提建议。另一块呢,是有实权的DMM,很小很集中,是人类可以完全理解和监管的,不用很聪明,只用鉴别建议的好坏。
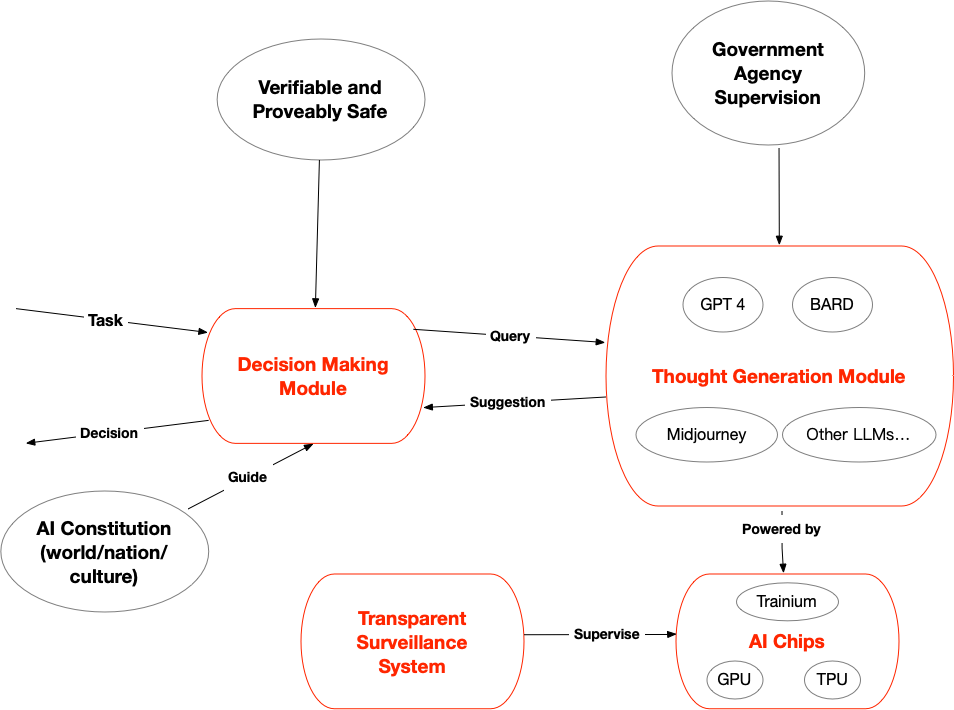
现在的 GPT4,BARD,以后的 GPT5,都应该设成没有实权的TLM,只能说不能做。
而DMM,这个负责做决定的模块,则需要谨慎再谨慎的设计。首先,我们得保证它是绝对安全的。好消息是,计算机中有专门的领域研究如何证明一个system的safety和verifiability。只要DMM足够小,就可以做到。
其次,DMM的逻辑涉及到伦理,法律,和道德。往大了说,我们有电车问题这种全人类都纠结的难题。往小了说,每个文化,每个国家,都有不一样的伦理观和道德观。所以可以想象,DMM的逻辑需要层层分级。在最上层,我们需要一套世界通用的AI宪法。在此基础上,每个国家和文化又有不同的宪法。在最底层,每个州,每个地区,甚至每个公司,或许都可以有自己额外的规章制度。
而要建立一套世界的宪法,则需要世界范围内民主的讨论(对不起超纲了,我只是一个程序员)。
一个致命漏洞
上面的设计看起来很美好,但有一个致命漏洞。我们怎么防止有心之人偷偷把不利于人类AGI释放出来,来祸害世界呢?
对此,我觉得需要两层的监管制度。在上层,对于每个大模型,我们都需要开源代码,然后有专业的机构去验证,去证明它只是一个TLM,只能提建议而无法执行。
在底层,控制芯片是必要的!因为大模型巨大的运算需求,只有拥有大量的高级AI芯片才能跑的起来。而这些芯片又极度稀缺,且只需掐断上下游供应链,就能准确的控制芯片的数量,监控到每一个芯片的归属。
我觉得需要一个透明的监督系统,让全世界的人都能随时知道,每一个AI芯片的位置,以及在上面正在跑的是什么模型。就像透明的核武器管理一样。
另外,我们可以在存有芯片的数据中心设置自毁系统,一旦发现开始跑上了图谋不轨的模型就能够随时override and shut down。实在不行,阿汤哥来炸掉也行,我可以当内应。
后记
有人说,技术是没有好坏的,只取决于它怎么被使用。我时常用这句话安慰自己。可是人工智能的革命是史无前例的,从来没有一种技术能够全方位的超脱人类和取代人类。如果AGI发展的好,可以想象我们的未来会无限光明,生产力大大提高,一个个科学问题被解开,环境难题被解决,脑机接口让我们变得更强大,甚至人类可以成为星际文明。如果AGI发展歪了。。。后果难以想象,我还想活100岁呢。
希望更多的人能关注这个问题,参与到讨论中来。
